Graphing Palo Alto Firewall statistics via Python, Telegraf and Grafana - Part 2

This is Part 2 of the Palo Alto metric fetch and graphing. See Part 1 for more details and backgroud information.
Prerequisites
I'm running all the software on Ubuntu 20.04 server and Python 3.10.2. Lesser versions should work also, though Python < 3 has not been tested (and should not be used anymore anyways).
- Palo Alto firewalls (PAN-OS 9.0, 9.1, 10.0 and 10.1 tested with these scripts)
- InfluxDB 2.x installed (1.x will also work but the Telegraf and Grafana configs are a bit different)
- Telegraf installed
- Grafana installed
Getting Palo Alto statistics using Python scripts
Part 1 contains more detail on how the scripts fetch the data and how they should be used.
Note: You can easily modify the script to save the data anywhere you like or for example perform data calculations and such before outputting the data. Also getting other data via the XML API can be easily implemented.
CPU and Packet Buffer statistics
#!/usr/bin/env python
import datetime
import logging
import requests
import json
import time
import urllib3
import argparse
import textwrap
import threading
import xml.etree.ElementTree as ET
sem = threading.Semaphore()
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
logging.basicConfig(level=logging.WARNING, format='[%(asctime)s] [%(levelname)s] (%(threadName)-10s) %(message)s', datefmt='%Y-%m-%d %H:%M:%S')
# Set the API Call URL
PAOpApiCallUrl = "https://{}/api/?type={}&cmd={}&key={}"
# Function for parsing the configuration
def parse_config(config_path):
with open(config_path, 'r') as config_file:
config_data = json.load(config_file)
return config_data
# Palo Alto API call function
def pa_apicall(url,calltype,cmd,key,firewall,unixtime):
logging.info('Parsing firewall %s (%s) system info', firewall)
result = requests.get(PAOpApiCallUrl.format(url, calltype, cmd, key), verify=False, timeout=5)
if result.status_code != 200:
logging.info("Palo Alto API call failed - status code: %i" % r.status_code)
return 1
# Acquire semaphore and parse the output
sem.acquire()
parse_output(firewall, unixtime, result)
sem.release()
return 1
# Parse and print output
def parse_output(firewall, unixtime, resource_info):
# Get the XML Element Tree
resource_info_tree = ET.fromstring(resource_info.content)
# Assign some help variables
cpu_count = 0
total_cpu_avg = 0
total_cpu_avg_calc = 0
dp_cores = 0
# Calculate the total CPU amount
for resource in resource_info_tree.findall(".//dp0/minute/cpu-load-average"):
cpu_count = len(list(resource))
# Get resource info and parse
for resource in resource_info_tree.findall(".//dp0"):
# Calculate and print average CPU info
for cpu in resource.findall("./minute/cpu-load-average/entry"):
if (cpu_count - int(cpu.find('coreid').text)) != cpu_count:
if (cpu_count > 2) and (cpu_count - int(cpu.find('coreid').text)) == 1:
pass
elif int(cpu.find('coreid').text) > 12:
pass
else:
dp_cores += 1
total_cpu_avg += int(cpu.find('value').text)
print("pacpuinfo,firewall=" + firewall + ",cpuid=" + cpu.find('coreid').text + " cpu-avg=" + cpu.find('value').text + " " + str(unixtime))
# Calculate average CPU from all dataplane cores
total_cpu_avg_calc = total_cpu_avg / dp_cores
print("pacpuinfo,firewall=" + firewall + ",cpuid=all cpu-avg=" + str(total_cpu_avg_calc) + " " + str(unixtime))
total_cpu_avg_calc = 0
total_cpu_avg = 0
dp_cores = 0
# Calculate and print maximum CPU info
for cpu in resource.findall("./minute/cpu-load-maximum/entry"):
if (cpu_count - int(cpu.find('coreid').text)) != cpu_count:
if (cpu_count > 2) and (cpu_count - int(cpu.find('coreid').text)) == 1:
pass
elif int(cpu.find('coreid').text) > 12:
pass
else:
print("pacpuinfo,firewall=" + firewall + ",cpuid=" + cpu.find('coreid').text + " cpu-max=" + cpu.find('value').text + " " + str(unixtime))
# Print resource-utilization
for sess_info in resource.findall("./minute/resource-utilization/entry"):
if sess_info.find('name').text == "packet buffer (average)":
print("pacpuinfo,firewall=" + firewall + ",packet_buffer=packet_buffer_avg packet_buffer_avg=" + sess_info.find('value').text + " " + str(unixtime))
elif sess_info.find('name').text == "packet buffer (maximum)":
print("pacpuinfo,firewall=" + firewall + ",packet_buffer=packet_buffer_max packet_buffer_max=" + sess_info.find('value').text + " " + str(unixtime))
def main():
# Print help to CLI and parse the arguments
parser=argparse.ArgumentParser(
formatter_class=argparse.RawDescriptionHelpFormatter,
description=textwrap.dedent('''\
Palo Alto Get CPU and packet buffer info for Telegraf
'''))
parser.add_argument('-f', type=str, dest='firewall_db', default="firewalls.json", help='File to read the firewall database from')
args=parser.parse_args()
# Config filenames
config_filename = "config.json"
firewall_filename = args.firewall_db
unixtime = time.time_ns()
# Output logging information for debug purposes
logging.info('Starting Palo Alto Get CPU info for telegraf')
logging.info('Parsing config %s and firewall database %s', config_filename, firewall_filename)
# Parse configuration files
config = parse_config(config_filename)
fw_config = parse_config(firewall_filename)
# Initiate jobs list
jobs = []
try:
# Parse the firewalls list
for firewall in fw_config["firewalls"]:
# Save the function calls into jobs list
thread_apicall = threading.Thread(target=pa_apicall, args=(firewall["ip"], "op", "<show><running><resource-monitor><minute><last>1</last></minute></resource-monitor></running></show>", config["apikey"], firewall["name"], unixtime))
jobs.append(thread_apicall)
# Start the jobs in list
for j in jobs:
j.start()
# Join the jobs in list
for j in jobs:
j.join()
except KeyboardInterrupt:
logging.info('KeyboardInterrupt')
logging.info('Ending')
if __name__ == "__main__":
main()
Automate the data gathering with Telegraf
We are using Telegraf to call the Python script with specific intervals to fetch the data and save it to InfluxDB.
In the configurations below, only the output and inputs are defined. Other Telegraf config must be present also.
# Define InfluxDB v2 output
[[outputs.influxdb_v2]]
urls = ["http://localhost:8086"]
token = "TOKEN"
organization = "ORG"
bucket = "panos_counters"
tagexclude = ["tag1"]
[outputs.influxdb_v2.tagpass]
tag1 = ["panoscounters"]
# Palo Alto CPU and Packet Buffer counters fetch
[[inputs.exec]]
command = "/usr/bin/python3 /panos_scripts/get_panos_cpu_packetbuffer_info.py"
data_format = "influx"
timeout = "15s"
interval = "1m"
[inputs.exec.tags]
tag1 = "panoscounters"
Verify data input in InfluxDB browser
Browse through the InfluxDB Data Explorer to verify that the data is coming to the proper Bucket and is getting written correctly.
Visualize data in Grafana
Below are example graphs and InfluxDB Flux queries to get and format the data. In addition, I'm using data variables (firewall names), you must configure these in the dashboard variable settings.
However, you don't have to use the data variables. You can change / remove the filters for firewall in the Flux queries below. The queries will then display everything in the same view, without the ability to filter the data in Grafana (which in turn would cause a lot of data displayed in one graph when data from multiple firewalls is visualized).
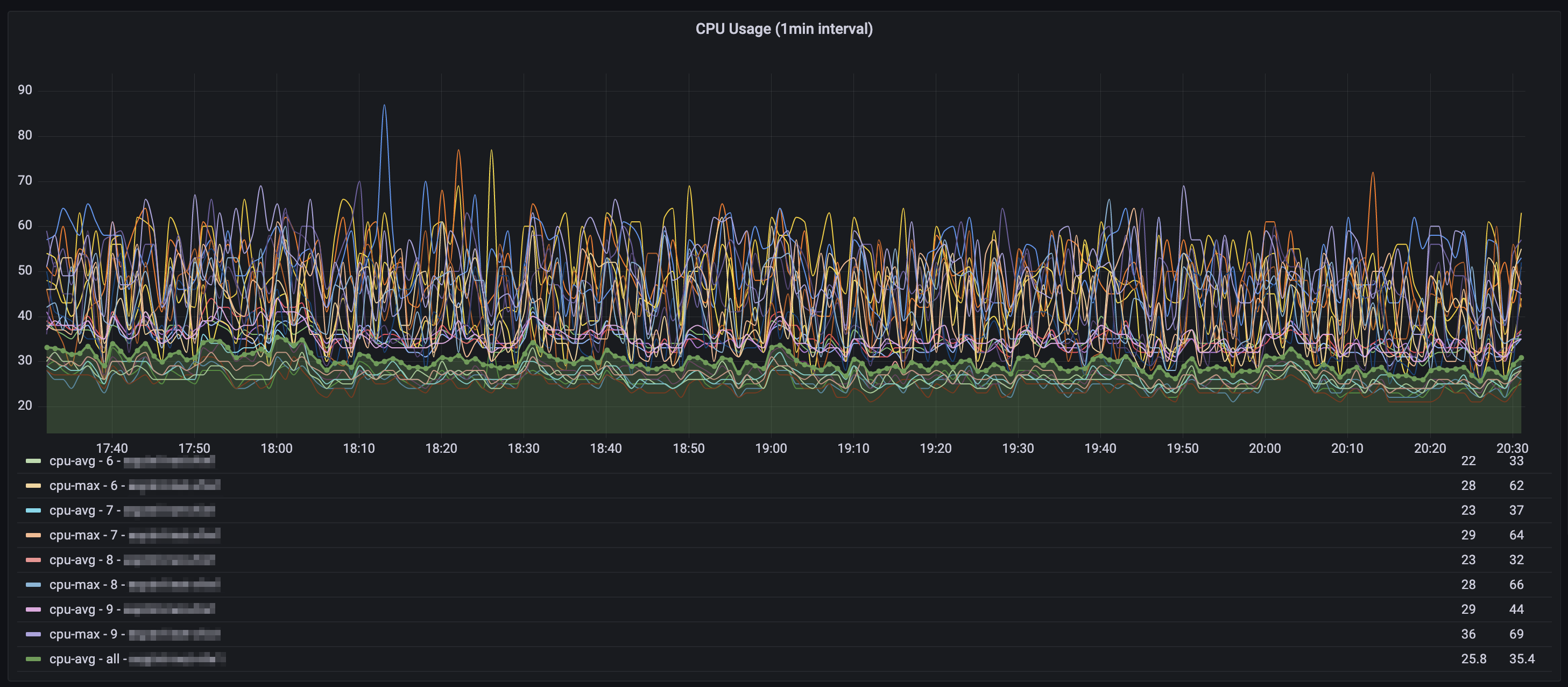
// Palo Alto - CPU Graph - 1min data (Time series graph)
from(bucket: "panos_counters")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "pacpuinfo" and r["_field"] == "cpu-avg" or r["_field"] == "cpu-max")
|> filter(fn: (r) => r["firewall"] =~ /${firewalls:regex}$/)
|> aggregateWindow(every: v.windowPeriod, fn: last, createEmpty: false)
|> yield(name: "last")
// Palo Alto - Packet buffer - 1min data (Time series graph)
from(bucket: "panos_counters")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "pacpuinfo" and r["_field"] == "packet_buffer_avg" or r["_field"] == "packet_buffer_max")
|> filter(fn: (r) => r["firewall"] =~ /${firewalls:regex}$/)
|> aggregateWindow(every: v.windowPeriod, fn: last, createEmpty: false)
|> yield(name: "last")
Example on how to grab the data variables from the InfluxDB data for usage in Flux queries. Configure these under Dashboard -> Variables.
from(bucket: "panos_counters")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "pasessioninfo")
|> keep(columns: ["firewall"])
|> distinct(column: "firewall")
|> keep(columns: ["_value"])
Conclusion
Following the steps above (and from Part 1) allows you to gather and visualize some very informative data from Palo Alto firewalls via the PAN-OS XML API.
All the scripts above can be found in the GIT repository